Arquitetura
Princípio central
O Atreides mantém regra de negócio no núcleo e infraestrutura nas
bordas. Isso vale tanto para o desenho do código quanto para o runtime: paths de
entrada, Airflow, MLflow e ClickHouse entram por infra; o control orquestra fluxos; o
domain/demand modela snapshots e contextos semânticos de treino; o
control/data_preparation define as portas genéricas de data-preparation;
infra/data_preparation/spark materializa e persiste snapshots canônicos; e
infra/data_preparation/polars executa treino e predição sobre os frames
materializados.
Dentro da plataforma maior, este repositório é o command side do contexto de forecasting. Ele recebe comandos, valida invariantes, persiste estado de escrita e dispara workflows duráveis no Airflow. Read models de produto, dashboards e consultas analíticas devem viver fora desta API. As exceções locais são endpoints operacionais estreitos, como health do processo HTTP.
Camadas internas
domain
- entidades, value objects e invariantes;
- concentra a semântica estável de
SeriesKey,ModelDefinition,ModelVersioneModelInstance; - sem I/O, framework ou contrato externo.
control
- casos de uso de ingestão, treino, promoção e submissão de workflows;
- depende de
portspara infra externa e boundaries realmente substituíveis; - trata identidade de série como
SeriesKeye consumo de histórico como payloads canônicos distintos para treino e forecast; - mantém contratos command-side compartilhados em
control/modeling/sharedquando treino, promoção, predição e configuração precisam do mesmo conceito, como configuração resolvida, catálogo de estratégias ou repositório deModelDefinition; - mantém composições entre comandos irmãos, como treino seguido de promoção, em
control/modeling/workflows, em vez de fazer um slice depender da implementação interna de outro; - resolve configuração ativa por
SeriesKeyemcontrol/modeling/config, antes de treino, avaliação, promoção, artefatos, auditoria e forecast consumirem horizonte, estratégia, receita de features e thresholds; - pode usar serviços in-process da própria camada quando não existe boundary de infra real, como o registry interno de estratégias.
domain/demand + control/data_preparation + infra/data_preparation
- modela
DemandSnapshotManifest,SeriesTrainingContext,TrainingDataseteSeriesHoldoutSplitno domínio; - concentra boundaries neutros de payload em
control/data_preparation/*, separando o payload de entrada do treino do payload de saída de forecast; - mantém nomes e validações estruturais de colunas no contrato canônico, para que estratégias e adapters não dependam entre si;
- deixa a implementação concreta desses payloads em adapters por responsabilidade: Spark para materialização/parquet e Polars para execução de treino/predição;
- concentra Parquet, normalização de schema e validação frame-native do histórico apenas no adapter infra;
- evita paridade artificial entre engines: cada engine mantém só o que o runtime realmente usa;
- executa split de holdout temporal sem materializar aggregates de demanda no caminho offline;
- evita forçar o
controla conhecer detalhes de leitura e agrupamento de dataset.
infra
- implementa
ports; - traduz HTTP, ClickHouse, Parquet, MLflow, JWT e storage para o modelo interno;
- concentra adapters, migrations, records e mapeadores ClickHouse em
infra/persistence/clickhouse/; - consome value objects neutros compartilhados, como os locators em
domain/shared/value_objects.py, sem empurrar detalhes de adapter paracontroloudomain.
infra/modeling
- implementa famílias concretas de forecast, como Nixtla;
- traduz o payload canônico de treino e o payload canônico de forecast para o formato exigido pela biblioteca final;
- depende do contrato canônico de frame, não dos adapters concretos de
infra/data_preparation.
Topologia operacional
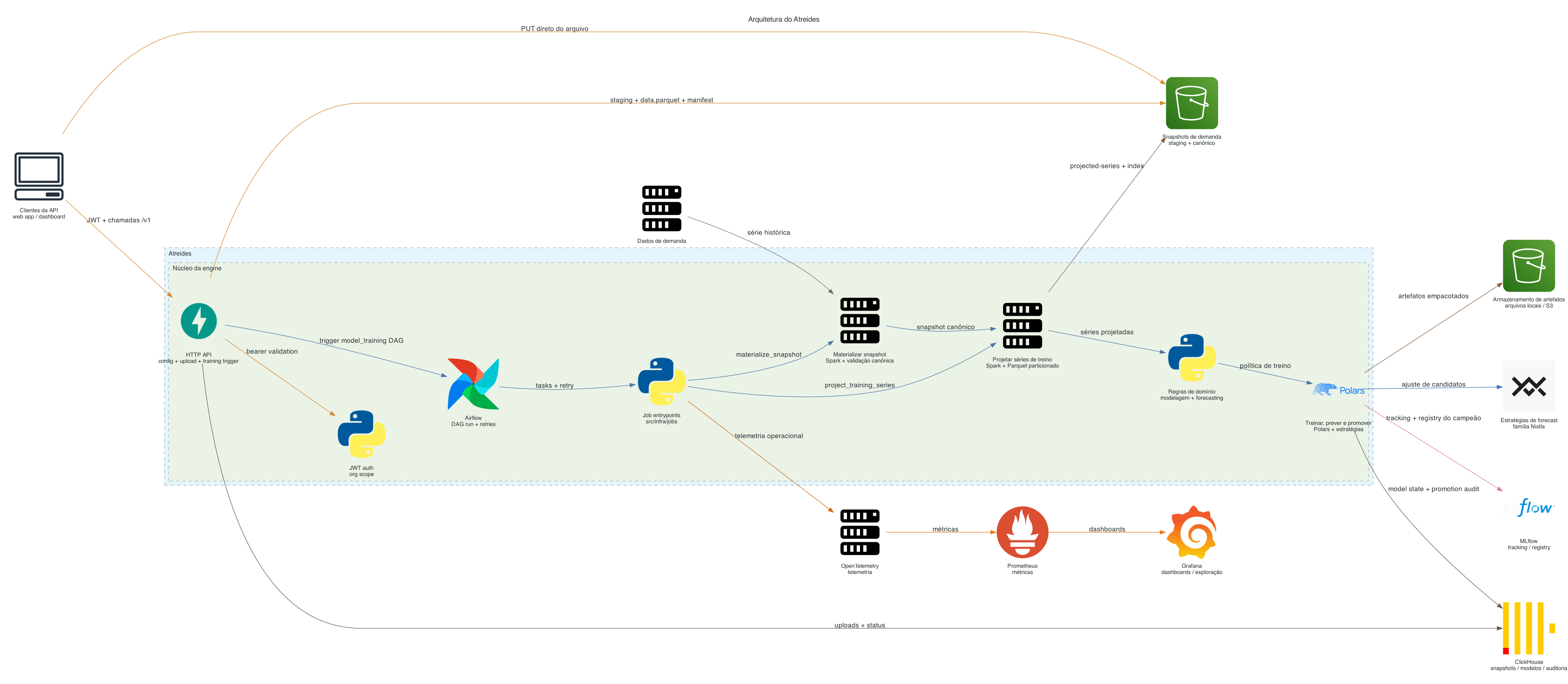
No runtime principal:
- a API só autentica, valida, cria snapshots e dispara DAGs;
- o Airflow executa materialização de snapshot, treino e promoção via
src/infra/jobs; - MLflow centraliza tracking de treino, packaging e registry sync dos campeões;
- ClickHouse guarda metadados, snapshots, modelos e auditoria.
Topologia da plataforma
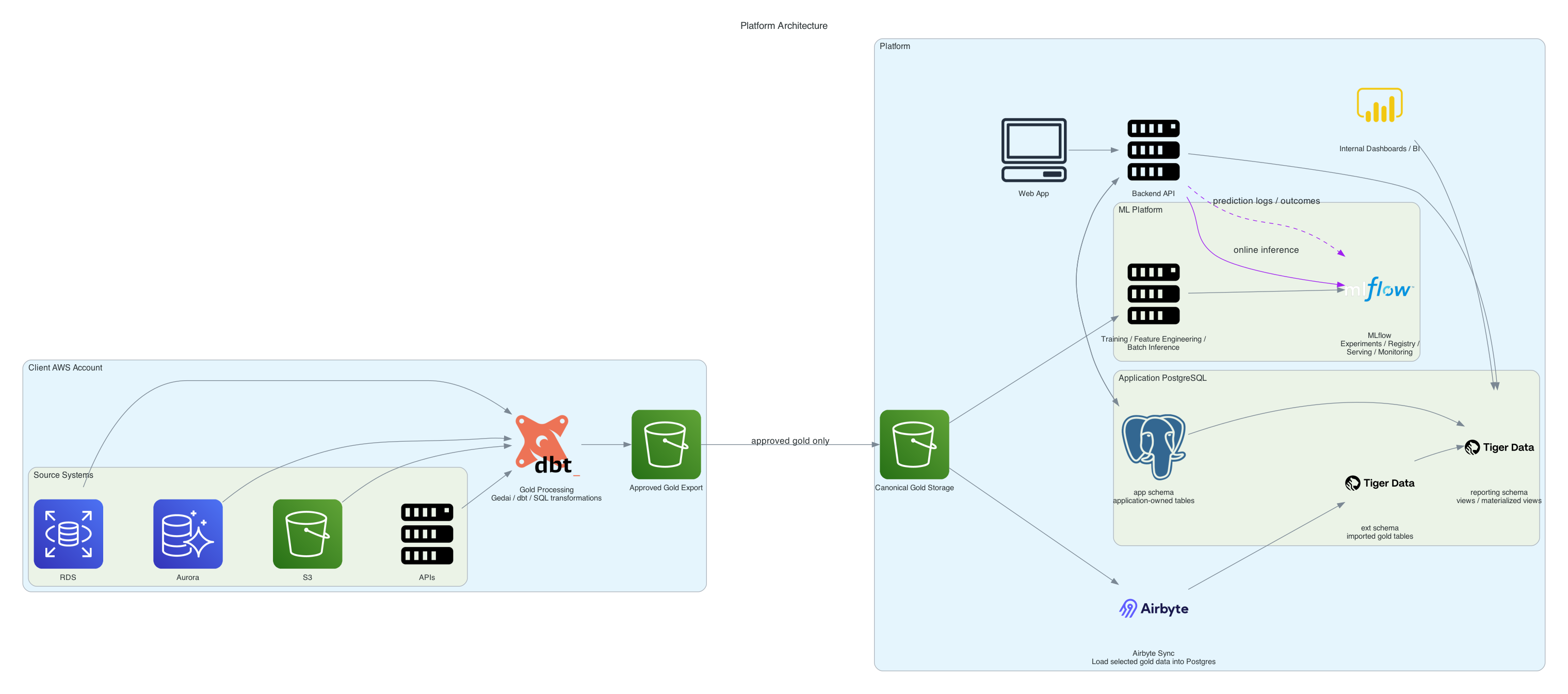
A plataforma recebe somente o recorte de demanda aprovado para treino.
O produto conversa com a engine por HTTP para comandos; a engine persiste o
estado write-side em ClickHouse, dispara DAGs no Airflow e conversa com storage e MLflow por infra,
enquanto o treino consome snapshots pelo boundary de data_preparation. O read
side da plataforma deve consumir projeções/eventos derivados desse estado de
escrita, sem transformar esta API em endpoint de consulta de negócio.
Regra de dependência
domainnão depende decontrol,control/data_preparation,infraneminfra/modeling.controldepende dedomaine abstrações de boundary.domain/demandconcentra a semântica de snapshot, série treinável e split temporal.control/data_preparationdefine as portas genéricas dedata-preparation.infra/data_preparation/sparkimplementa materialização/parquet einfra/data_preparation/polarsimplementa execução de treino/predição sobre os frames preparados.infraimplementa integrações externas e transporte.infra/modelingimplementam famílias concretas de modelagem.
Regra prática:
- não criar
portapenas para encapsular um helper ou serviço interno do próprio processo; - criar
portquando ele protege uma integração externa, uma dependência de runtime, ou uma implementação que realmente pode variar. - deixar o boundary de
data_preparationexpor unidades úteis para treino. Hoje isso significa datasets preparados por série, splits de holdout e payloads genéricos de entrada/saída, não listas de aggregates materializados cedo demais.
Quando ler o que
- Modelo de domínio para invariantes e aggregates.
- Fluxos principais para snapshot, treino e promoção.
- Data-preparation flow para o fluxo detalhado de dados e responsabilidades de componentes.
- Projeção de séries de treino para a etapa Spark que transforma snapshot canônico em partições por
SeriesKey. - Control plane vs data-preparation para a separação entre estado durável e frames transitórios.
- Modelos ML para as integrações concretas de modelagem.
- Nixtla para o comportamento das estratégias Nixtla.
- Airflow e jobs para DAGs, tasks e retry.
- Storage e artefatos para fontes de verdade e convenções de path.
- Configuração de model definition para payloads e combinações válidas.
- Code map para localizar os módulos no repositório.