Arquitetura híbrida da plataforma
Resumo
A arquitetura híbrida mantém o processamento de dados no ambiente do cliente e exporta para a plataforma apenas a gold table aprovada. Esse desenho reduz a movimentação de dados brutos, preserva fronteiras de responsabilidade e concentra em nossa infraestrutura apenas o que é necessário para modelagem, serving, reporting e dados próprios da aplicação.
Diagrama de referência
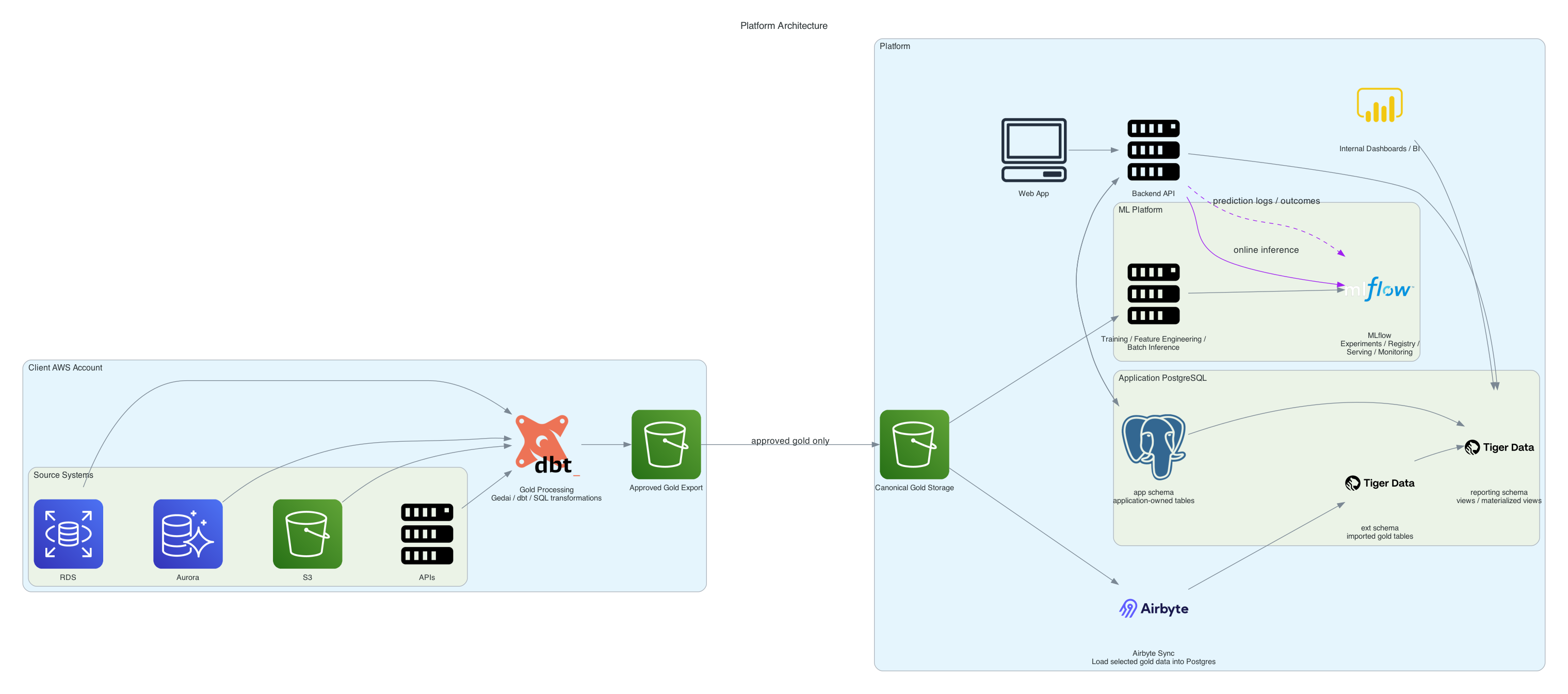
O cliente prepara e aprova a camada gold no próprio ambiente; a plataforma recebe somente esse recorte em S3 e o reutiliza para ML, PostgreSQL e consumo de aplicação.
Leitura do diagrama por domínio de responsabilidade
Ambiente do cliente
- os sistemas fonte continuam no perímetro do cliente (
RDS,Aurora,S3, APIs); - o enriquecimento e a padronização acontecem no pipeline local de transformação (
Gedai,dbt, SQL); - somente a saída curada e aprovada (
Approved Gold Export) cruza a fronteira para a plataforma.
Infraestrutura da plataforma
- o bucket canônico em
S3recebe a gold table exportada e se torna a base comum para treino, engenharia de atributos e inferência em lote; - a camada de ML centraliza execução de pipelines, tracking, registry, serving e monitoramento via
MLflow; - um sync seletivo carrega os dados gold necessários para o PostgreSQL da aplicação;
- o PostgreSQL separa dados por responsabilidade:
app schema: tabelas operacionais e metadados próprios da aplicação;ext schema: tabelas importadas da gold table;reporting schema: views e materialized views que combinam dados importados e dados da aplicação.
Fluxo ponta a ponta
- Os dados operacionais permanecem na conta do cliente, próximos aos sistemas de origem.
- O cliente executa o processamento até a camada gold no próprio ambiente.
- Apenas a gold table aprovada é exportada para nossa AWS e persistida em
S3. - A plataforma usa esse dataset para treino de modelos, feature engineering e inferência em lote.
- Quando necessário para consultas operacionais e analytics, um subconjunto da gold table é sincronizado para o
ext schemano PostgreSQL. - O
reporting schemamonta views sobre dados importados e sobre oapp schema, que guarda entidades e estados próprios do produto. - O backend atende a aplicação e dashboards; para inferência online, ele consulta a camada de serving e devolve previsões ao produto.
Por que este desenho existe
| Decisão | Motivo |
|---|---|
| Processar dados no ambiente do cliente | aproxima o pipeline das fontes, reduz cópia de dados sensíveis e respeita governança local |
| Exportar apenas a gold table | limita o contrato entre ambientes ao dado já curado e aprovado para consumo |
| Centralizar ML em nossa AWS | concentra registry, tracking, serving e monitoramento em uma operação única |
Manter app schema separado de ext/reporting | evita misturar dados próprios da aplicação com datasets importados |
| Construir views no PostgreSQL | simplifica consumo por backend, dashboards internos e BI |
Limites e garantias operacionais
- a plataforma não depende de replicação integral do ambiente do cliente; ela consome apenas o recorte necessário para previsão e reporting;
- a gold table em
S3é o ponto de entrada compartilhado entre pipelines de ML e sincronização analítica; - dados de aplicação continuam vivendo em tabelas próprias do PostgreSQL, mesmo quando relatórios dependem de joins com o dataset importado;
- a separação entre
S3,MLflowePostgreSQLpermite evoluir serving, treinamento e reporting sem acoplar o domínio da aplicação ao pipeline de ingestão do cliente.
Relação com a arquitetura interna do código
Esta página descreve a topologia de infraestrutura e fluxo de dados entre ambientes. Para a arquitetura interna da forecast-engine em camadas (domain, application, adapters, contracts), veja Visão de camadas.